Optimizing Public Transportation (Udacity)
Nov 2, 2019
Simulate and display the status of train lines in real time by construction of a streaming event pipeline around Apache Kafka and its ecosystem using public data from the Chicago Transit Authority.
Architecture #
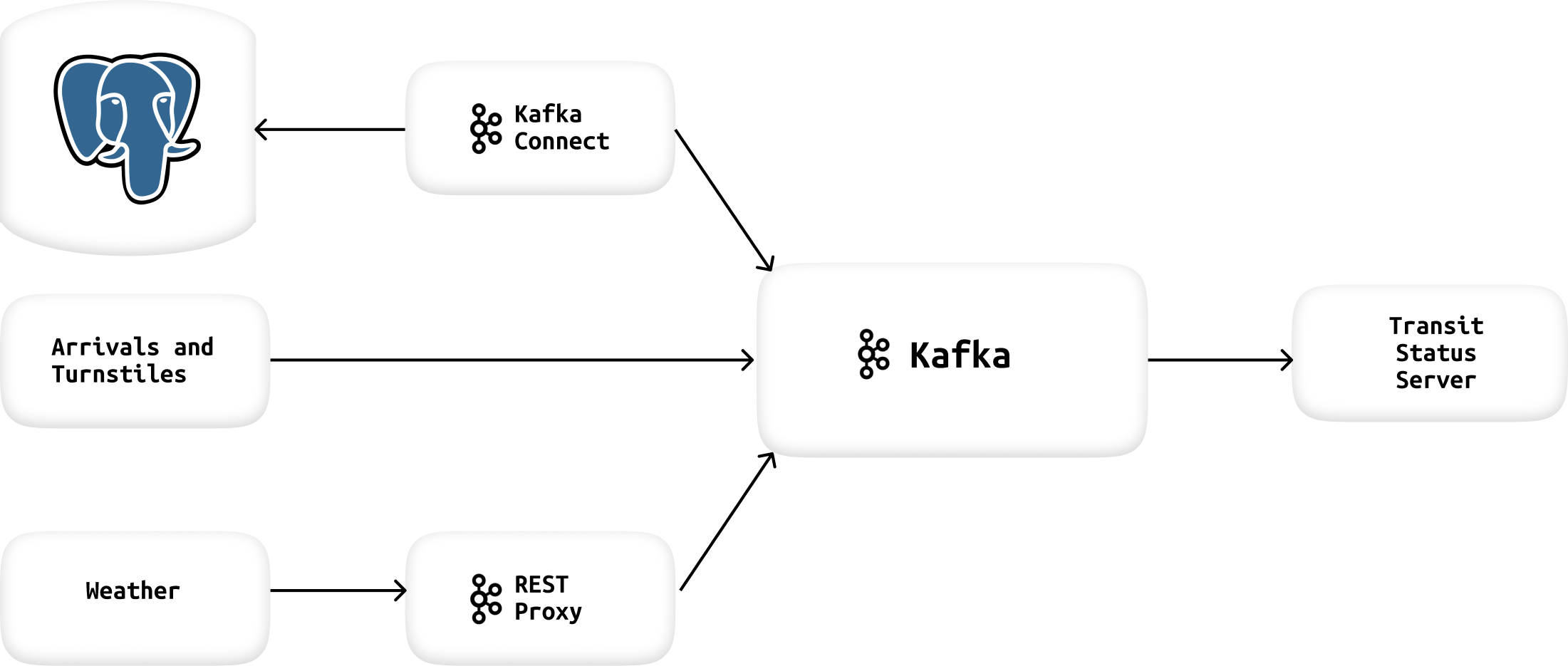
Creating Kafka Producers #
To create a Kafka Producer we must define a model and schema and then configure the kafka producer to emit some events.
Producer #
A producer partitioner maps each message to a topic partition, and the producer sends a produce request to the leader of that partition. The partitioners shipped with Kafka guarantee that all messages with the same non-empty key will be sent to the same partition. refer, confluent-kafka-python, code
Schemas: Schema Registry is a distributed storage layer for schemas which uses Kafka as its underlying storage mechanism refer, confluent-kafka-python, code
Station #
A topic is created for each station in Kafka to track the arrival events. code
Turnstile #
A topic is created for each turnstile for each station in Kafka to track the turnstile events which are then joined with Avro key and value. code
Configure Kafka REST Proxy Producer #
We send weather readings into Kafka by using Kafka’s REST Proxy. So we create a value schema for weather event and configure weather model to emit events to Kafka REST Proxy. kafka-REST, code schema, code
Configure Kafka Connect #
To extract station information from our PostgreSQL database into Kafka. We use the Kafka JDBC Source Connector. kafka-connect
We create a connector like this.
Configure the Faust Stream Processor #
We use Faust Stream Processing library to convert the raw station table data into a better format.
Configure the KSQL Table #
KSQL is used to aggregate turnstile data for each of our stations.
Creating Kafka Consumers #
Now that we have some date we can create a consumer to consumen the data. Creating a consumer is similar to a producer.
confluent-kafka-consumer, consumer, consumer-models
Running #
Configure kafka and all the requirementes properly and check if all the services are up and running including Kafka REST Proxy Schema Registry Kafka Connect KSQL PostgreSQL Zookeeper
To run the producer: #
cd producers
python simulation.py
To run the Faust Stream Processing: #
cd consumers
faust -A faust_stream worker -l info
KSQL: #
cd consumers python ksql.py
To run the consumer: #
cd consumers
python server.py